Generalizing to
a Population:
COMPLEX MODELS continued
 REPEATED MEASURES MODELS
REPEATED MEASURES MODELS
So far, all the models we have looked have been
for data from cross-sectional or descriptive studies. These are
studies in which each person is observed only once, so for each variable you have
only one value per person. To put it another way, each row in the data set is
for a different subject.
Now, what about longitudinal studies, in which people are observed more
than once? In particular, what about interventions or experiments,
where you compare values of a dependent variable before and after you try something
like a training program or a potentially active drug? You can analyze data from
these studies with the procedures used for cross-sectional data only
if you can assume that the residuals are uniform--have the same standard deviation--for
each of the repeated measurements. But in general, you can't assume such
uniformity: subjects will show more variation on some repeated measurements
than on others, usually because of differences between measurements in the effects
of time or the treatment. So you have to use repeated-measures models.
We'll start on this page with the simple case of only two trials for only one
group of subjects (no between-subject effect). On the next
page I'll extend it to several groups (a between-subjects effect, e.g. an
experimental and control group). Then I'll deal with more than two trials, first
without a between-subjects effect, then with
a between-subjects effect, before I deal with other
repeated-measures models including the simple, robust approach of within-subject
modeling. Then there is a page on how to use the mixed
procedure in the Statistical Analysis System, with links to . Finally, I
devote a page to a problem that can arise in repeated-measures analyses, regression
to the mean. But first, some other resources I have created since writing
these pages: a slideshow, a stand-alone article, and some spreadsheets.
Slideshow on Repeated Measures
For a Powerpoint slideshow (340 kB) dealing
with most aspects of repeated-measures analyses, click
here. I presented this talk at the 2003 annual meeting of the American College
of Sports Medicine. The sections are Basics (analysis by ANOVA, within-subject
modeling, and mixed modeling; fixed and random effects; individual responses
and asphericity), Accounting for Individual Responses, Analyzing for Patterns
of Responses, and Analyzing for Mechanisms. The information in the slide show
complements the information on these pages. Read both.
Articles and Spreadsheets for Straightforward
Repeated Measures
I have created spreadsheets for analysis
of repeated-measures data from controlled trials and crossovers. You add the
raw observations, the spreadsheet does the rest. I have also written articles
at the Sportscience site explaining important issues in such analyses, and how
the spreadsheets address them. (Links to the Sportscience articles will not
work if you are using a copy of these pages off-line.)
Click to view the 2006 article,
which explains the use of a covariate and has links to earlier articles. See
also an article on the different
kinds of controlled trials in the 2005 issue, which explains the names I
have used below for the spreadsheets.
Click to download the spreadsheet
for pre-post parallel-groups trials, the spreadsheet
for post-only crossovers (which also works for the paired t-test model on
this page), and the spreadsheet
for pre-post crossovers. The following links will download earlier version
that do not include the covariate and other enhancements: spreadsheet
for controlled trials, spreadsheet
for crossovers, and fully controlled
crossovers.
|
|
Paired T Test or
Repeated-Measures ANOVA with two trials and no
between-subjects effect
|
model:
numeric <= (subject) trial
example: jumphgt <= (athlete) time
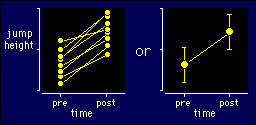
Don't try to understand the model yet. Just look at
the example in the figure, which shows individual values on the left and means
and standard deviations on the right. There is one measurement on each of eight
athletes before (pre) and after (post) a training program aimed at increasing
jump height, with no control group. This sort of design is sometimes described
as one in which the subjects "act as their own controls", although this description
fits any longitudinal study, whether or not there is a control group.
The results can be displayed as shown in the left-hand panel, with pre and
post heights linked for each subject. The right-hand panel shows the more usual
way of connecting the means by a line. By the way, it's wrong to use a bar graph,
because the pre and post data are from the same subjects.
It doesn't look anything like it, but this model is actually a
two-way ANOVA. If I'd drawn bars instead of points for the pre and
post heights, you might have seen that it is at least a one-way
ANOVA, time being the nominal effect (with two levels, pre and post),
and height the dependent numeric variable. So let's get started with
jumphgt <= time.
The other effect is hidden in the right-hand figure, but it's
clear in the left-hand side: the identity of the subjects. We
introduce this variable as a way to link each subject's measurement
of height at the pre and post times. Hence the full model:
jumphgt <= (athlete) time. In the general
model, one term in the ANOVA is the identity of the subjects, and the
other term is the identity of the time points or trials.
Hang on. Why (athlete) rather than athlete? Well, the variable representing
the identity of the subjects is a bit different from all the other variables
we've met so far. The subjects are usually a random sample of a population,
so this variable is known as a random effect. If we repeated the study,
we could have a different sample of subjects, each with different values drawn
randomly from the population. In contrast, the identity of the time points is
a fixed effect, because this variable would have the same values and
levels (pre and post) in any repeat of the study. Look back at the nominal variables
in the other models we've dealt with and you'll see that they are all fixed
effects. For example, sex always has values male or female in every sample,
and we assume the effect of maleness or femaleness is the same for every male
or female. For more information on fixed and random effects, see the slideshow
on repeated measures. If you want to work with mixed models, make sure you
get familiar with my "hats" metaphor for random effects, as explained
in the slideshow.
So, I've put parentheses around the subject term to indicate that it's a random
effect, and to let you know that stats programs don't normally include the subject
term in the model in the way that I have here. If I left the parentheses out,
I would imply that the subject term is a fixed effect. It is possible
to analyze your data as a straightforward non-repeated-measures ANOVA with the
subject term as a fixed effect, but the results you get are appropriate only
for repeated-measures data that have uniformity of residuals. I deal with that
later under the heading sphericity or covariance
structure.
We don't have the interaction term athlete*time in the model, partly because athlete is a
random effect, and partly because we would need multiple measurements
for subjects at the pre and post time points for the interaction term
to make any sense. Let's leave aside this complexity.
It all sounds awfully complicated, but in practice it's straightforward. You
have two lots of measurements performed on the same subjects, and all you want
to know is how the means have changed. Most stats programs can do that for you
without you having to worry about models like the above. All you do is click
up a paired t test, which produces a p value for the difference in the
means, and hopefully a confidence interval. The paired t test has the same internal
workings as the unpaired t test, which is why they share the same name.
On the next page we'll add a control group. After all, the
athletes might jump higher in the post test simply because they have
learned how to do the test, not because they responded to your
training program. A group that does everything the same as the
experimental group, other than the training program, "controls" for
this and other problems. But the main reason I'm talking about a
control group now is to explain the terminology in the heading for
this page. Having a control group in a repeated-measures design is an
example of a between-subjects effect, because there are
different subjects in the control and experimental groups. Hence
no between-subjects effect in the title of this section. Time
or trial is a within-subjects effect, because the same
subjects experience the different levels of that effect.
Go to: Next · Previous · Contents · Search
· Home
Last updated 5 Mar 2012